Так как Elasticsearch помешан на скорости выполнения запроса в нём используется денормализация. Идея состоит в том, чтобы вся информация, относящаяся к объекту, была собрана в одном месте. Это означает, что вам нужно хранить избыточные копии данных в каждом документе вместо использования какого-либо типа отношений между различными индексами.
Денормализация обеспечивает лучшую производительность, поскольку нет необходимости выполнять вложенные соединения (join) при запросе данных. Кроме того, _source сжимается, что снижает место на диске.
Денормализация данных оптимизирована для операций чтения, что ускоряет поисковые запросы.
Пример денормализации
Возьмём для примера ситуацию с использованием неких машин некими людьми.
Список наших пользователей:
User1
User2
User3
Список наших машин:
BMW X5
BMW X6
KIA RIO
Допустим, что User1 использовал BMW X5, User2 - KIA RIO, User3 - KIA RIO и BMW X6.
Если бы мы представляли это в модели БД, то структура была бы следующая:
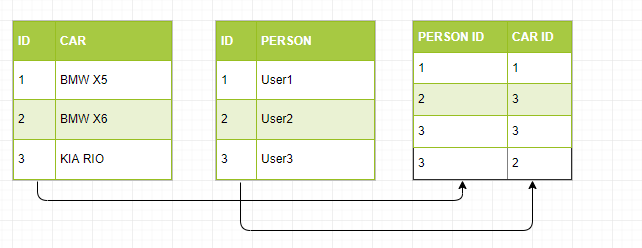
В Elasticsearch это будет выглядеть так:
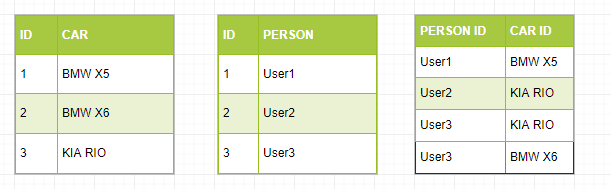
Преимущество денормализации
После денормализации ваших данных вся информация находится в одном месте. Теперь вы можете искать авто и их владельцев с помощью одного запроса. А поскольку вся информация находится в одном месте (таблица справа), вам не нужно выполнять вложенные поиски, чтобы получить результат. Elasticsearch - это поисковая система, поэтому она оптимизирована для поиска даже с моделированием данных.
Тем не менее не существует механизма, обеспечивающего согласованность денормализованных данных с исходным документом. Вам следует избегать денормализации данных, которые могут часто меняться (update).

Комментарии