Немного я конечно запоздал с изучением этой технологии, но как говорится лучше поздно чем никогда. В этой статье я попытаюсь максимально понятно разобрать архитектуру Kubernetes, какие компоненты за что отвечают.
Самое первое что нужно запомнить про Kubernetes это то что система считается распределённой, т.е. множество компонентов размещены на разных узлах (устройствах). Эти узлы могут быть как виртуальными, так и физическими, но лучше конечно физические. Всё это вместе называется кластером Kubernetes, который изображён на схеме ниже.
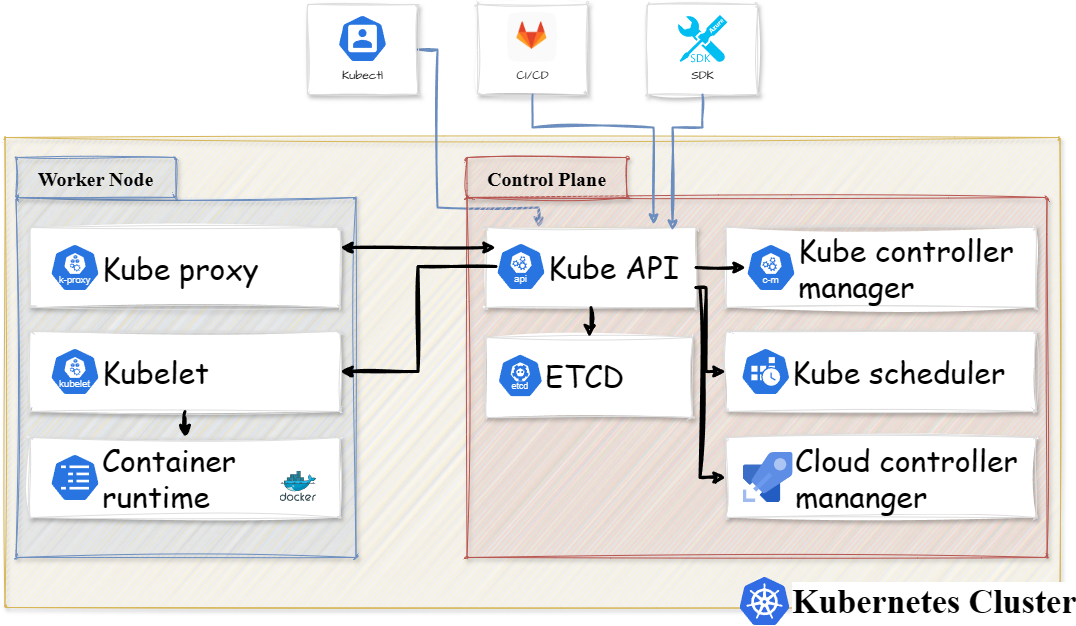
Как вы уже догадались из схемы выше каждый кластер Kubernetes состоит из рабочих узлов (worker nodes) и узлов управления (control plane nodes).
Рассмотрим поподробнее каждый из типов узлов.
Рабочий узел (worker node)
Для начала давайте разберёмся что такое под (pod) в Kubernetes, потому как слышать это слово вы будете часто. Под — это абстрактный объект Kubernetes, представляющий собой группу из одного или нескольких контейнеров приложения.
Эти узлы (Рабочий узел) отвечают за работу контейнеров используя среду контейнеризации, например, такую как containerd. Каждый рабочий узел в кластере Kubernetes имеет необходимые компоненты для работы с контейнерами. Ваш кластер может состоять и из одного рабочего узла, но чем больше, тем лучше.
Рабочий узел (worker node) имеет следующие компоненты:
kubeletContainer runtimekube-proxy
На рабочий узел (worker node) возлагаются следующие функции:
- Конечно же самый первый и основной - это запуск контейнеров
- Выдача ip адресов
- Управление хранилищем данных
- Распределение ресурсов
В итоге получается, что Kubernetes запускает ваше приложение помещая контейнеры в поды на рабочих узлах (worker nodes).
Имя рабочего узла (worker node name)
Как и во многих других системах идентификация рабочего узла происходит по имени, поэтому рекомендуется выдавать такое имя, по которому вы сразу поймёте, что это за рабочий узел и где он находится. Естественно имя рабочего узла должно быть уникальным.
Узел управления (control plane node)
Узел управления (control plane node) отвечает за управление контейнерами и также поддерживание рабочего состояния кластера, также может использоваться название Master Node. В кластере может быть несколько узлов управления, и каждый узел управления имеет следующие компоненты:
kube-apiserverkube-schedulerkube-controller-manageretcdcloud-controller-manager
Компоненты рабочего узла (worker node components)
Конечно же мы просто обязаны теперь рассмотреть все компоненты по порядку.
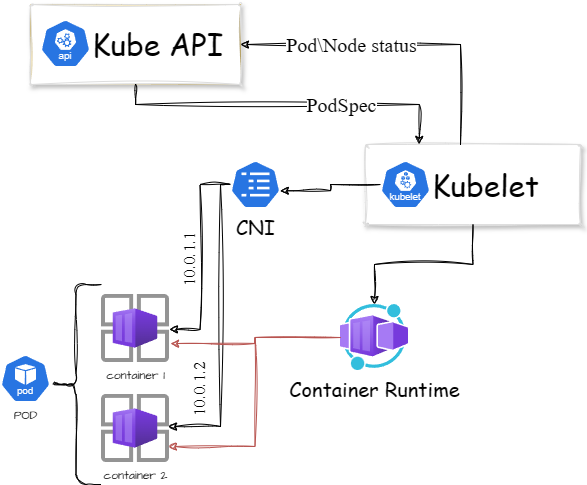
Kubelet
Kubelet - это агент, который запущен на каждом рабочем узле (worker node) как демон в системе, управляемый systemd. Этот демон отвечает за регистрацию всех рабочих узлов в кластере, используя при этом kube-apiserver. Также, когда говорим о Kubelet стоит упомянуть и о podSpec (спецификация подов). Это YAML или JSON файл, в котором указывается какие контейнеры должны быть запущены на конкретном узле, а также их характеристики, такие как ЦПУ, ОЗУ и т.д. Этот файл в первую очередь рабочие узлы получают от kube-apiserver через нашего героя - Kubelet.
Также Kubelet используется для отслеживания состояния подов и работы с системой контейнеризации, например, скачивание образов, создание или удаление контейнеров.
Вот за что отвечает Kubelet:
- Создание, удаление и модификация контейнеров
- Отвечает за монтирование томов для подов
- Сбор и предоставление данных о состоянии узлов и подов
Помимо kube-apiserver спецификацию подов (podSpec) Kubelet может получить и из файла по HTTP. Используется для статических подов в Kubernetes (Kubernetes static pods). Такие поды контролируются конкретно Kubelet, не с помощью kube-apiserver.
Ещё немного фактов о Kubelet:
- Использует
CRI(container runtime interface), который используется для работы с контейнеризацией - Использует
CSI(container storage interface) для конфигурации блочных томов - Используя протокол
HTTPпредоставляет возможность трансляции логов - Используя плагин
CNIдля назначения подам ip-адресов, настройки файрволла и необходимых роутов
После всего изложенного про Kubelet получаем следующую схему:
Kube proxy
Тут будет немного посложнее, для начала давайте разберёмся что такое сервис в Kubernetes . Под сервисом подразумевается какое-то количество подов собранные в одну группу. Также благодаря сервису поды получают внутренний или внешний трафик. Когда вы создаёте сервис он получает виртуальный ip-адрес, также называемый clusterIP. Этот виртуальный ip-адрес доступен только внутри кластера Kubernetes.
Объект Endpoint содержит все IP-адреса и порты подов в рамках объекта Service. Контроллер Endpoint отвечает за ведение списка IP-адресов подов (конечных точек). Контроллер сервиса отвечает за настройку конечных точек службы.
Последнее что еще нужно знать это то, что вы не сможете пропинговать clusterIP, но сможете пропинговать ip-адреса подов.
Теперь наконец-то про Kube proxy. Kube proxy - это демон, который запущен на каждом рабочем узле. Это прокси компонент, благодаря которому возможно использование сервисов Kubernetes. Он в основном проксирует UDP, TCP и SCTP для подов и не понимает HTTP.
Если просто, то благодаря Kube proxy при обращении к сервису (clusterIP) создаются правила, благодаря которым через виртуальный ip-адрес сервиса доступ предоставляется к ip-адресам подов. Поэтому и называется прокси.
Kube proxy обращается к kube-apiserver для получения данных о сервисе (clusterIP) и о ip-адресах, портах для подов. Конечно при изменении этих данных он сразу же применяет их.
Для перенаправления трафика Kube proxy может использовать одну из следующих технологий:
IPTables: Знакомая штука для любителейLinux, которая используется в Kube proxy по умолчанию. Для каждого сервиса создаются свои правилаIPTables. Благодаря этим правилам весь трафик приходящий на clusterIP перенаправляется на нужный под. Какому из подов перенаправить трафик выбирается случайным образом. После выбора весь последующий трафик будет перенаправляется именно выбранному поду, пока он не станет недоступным (сам под).IPVS: Думаю, что использовать этот тип будут не многие, так как его рекомендуется использовать если у вас вдруг в кластере Kubernetes используется более 1000 сервисов.Kernelspace: Используется только в Windowsnftables: это преемникIPtables, который разработан, чтобы упростить работу и повысить эффективность. Но необходимо проверить вышел ли он из стадии Альфа-функции
Container Runtime
Container Runtime - это программный компонент, необходимый для запуска контейнеров. Этот компонент собственно отвечает за любые манипуляции с контейнерами, например, создание контейнера, скачивание образов и т.д.
В качестве среды контейнеризации может использоваться CRI-O, Docker Engine, containerd, Mirantis Container Runtime. Среда контейнеризации для Kubernetes должна быть совместима с Container Runtime Interface (CRI). Это значит что среда контейнеризации должна иметь интерфейс CRI и поддерживать CRI APIs.
Также мы уже знаем, что благодаря Kubelet есть список того какие контейнеры нам нужно запустить и с каким характеристиками. Этап создания этих контейнеров выглядит так:
- Когда поступает запрос на под от kube-apiserver, kubelet обращается к демону среды контейнеризации, чтобы запустить необходимые контейнеры через интерфейс
CRI. - Среда контейнеризации запускает эти контейнеры
Компоненты узла управления (control plane node components)
И конечно же рассмотрим все компоненты узла управления.
kube-apiserver
Самый главный компонент в кластере Kubernetes, который предоставляет собственно api для Kubernetes. Считается хорошо масштабируемым и высокопроизводительным одновременно.
Чаще всего к kube-apiserver обращается конечный пользователь и другие компоненты кластера, например, Kubelet. Изредка к нему также могут подключаться разные системы мониторинга, если вы их настроили конечно.
Когда вы используете утилиту kubectl для управления кластера вы по сути работаете с kube-apiserver через HTTP REST APIs, только в удобном для вас виде. Каждая ваша команда, выполняемая через kubectl преобразуется в запросы, которые уже в последствии обрабатывает kube-apiserver.
Дальше сам kube-apiserver обращается к другим компонентом для выполнения команд. Коммуникация между kube-apiserver и другими компонентами происходит через TLS соединения.
Компонент kube-apiserver также имеет свой прокси (apiserver proxy), который используется для доступа к ClusterIP из-за пределов кластера.
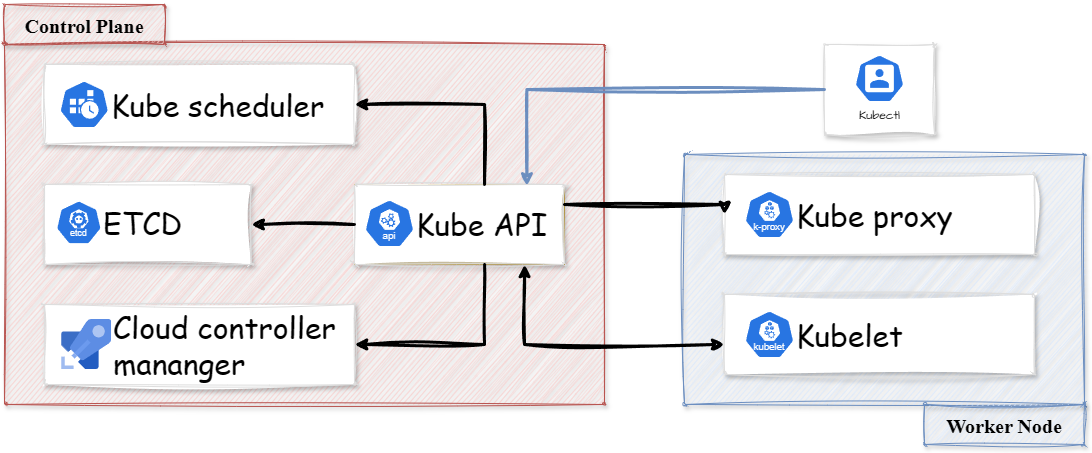
Kube-apiserver в кластере Kubernetes отвечает за следующее:
Управление API: выступает в роли шлюза для всех API запросовАутентификация и Авторизация: предоставляет услуги аутентификации для всех компонентов в кластере используя сертификаты, токены и HTTP-аутентификациюОбработка API запросов- Также является единственным компонентом, который обращается к etcd
- Занимается координацией всех процессов между компонентами узла управления и компонентами рабочего узла
Кстати у kube-apiserver есть функция которая даёт вам возможность писать свой собственный API, подробнее тут.
Когда вы создайте сервер, на котором будет расположен kube-apiserver задумайтесь о его безопасности, как минимум это не должен быть сервер с доступом к нему из вне. Иначе можете оказаться в таком вот неудачном списке.
etcd
По сути является базой данных в кластере Kubernetes. Так как сам Kubernetes является распределённой системой, что-то общее между узлами всё-таки должно быть. Etcd используется как средство обнаружения служб и база данных.
Сам etcd является open-source приложением, выступающим как хранилище для данных типа ключ-значение.
В Kubernetes он используется потому что обладает следующими функциями:
Гарантированная доставка: Если какое-то обновление выполнено на одному узлу, оно точно будет доставлено всем другим узлам в сетиРаздельность: предназначен для работы на нескольких узлах в виде кластераАлгоритм raft: etcd использует алгоритм консенсуса raft для обеспечения строгой согласованности и доступности. Для примера компонент orderer в hyperledger fabric тоже использует этот алгоритм.
Когда вы используете kubectl для просмотра каких-то данных в кластере Kubernetes вы по сути вытаскиваете эти данные из etcd. Также, когда вы запускаете новые поды информация о них, помещается и хранится в etcd.
Вот что ещё будет не лишним знать о etcd:
- etcd хранит все конфигурации, статусы и метаданные каждого объекта в кластере Kubernetes
- когда вы используете метод
Watch()черезAPIответ вы также получаете из данных, которые хранятся в etcd - etcd как и многие сервисы предоставляет свой
APIдля работы с ним, который конечно же использует kube-apiserver - все объекты в кластере etcd по умолчанию хранит в директории
/registry
kube-scheduler
kubik-kube-scheduler.drawio.png
Основная задача kube-scheduler является планирование запуска подов на рабочих узлах (worker nodes). При развертывании пода вы указываете требования к процессору, памяти и другим характеристикам пода kube-scheduler обрабатывает ваш запрос и выбирает самый лучший для этого рабочий узел, который соответствует требованиям.
Отсюда возникает логичный вопрос как именно он определяет какой рабочий узел использовать? Для того чтобы выбрать подходящий узел kube-scheduler использует операции фильтрации и оценки.
- Используя фильтрацию он находит подходящие узлы, на которых можно разместить поды. Если вдруг у вас несколько подходящих узлов, то он выберет все. Если же нет ни одного подходящего узла, то поды останутся висеть в очереди на размещение.
- После фильтрации запускается процесс оценки, в котором оценивается насколько тот или иной узел соответствует характеристикам подов. Если у вас слишком большой кластер, то этот процесс может занять какое-то время. Параметр
percentageOfNodesToScoreзадаёт минимальное количество узлов в кластере для оценки в процентном соотношении. По умолчанию это 50%, но если кластер очень большой, то это значение равняется 5%. - В итоге узел с самым большим рангом будет выбран для размещения подов. Если же найдётся несколько узлов с одинаковыми рангами, то выберется первый случайный.
- После выбора узла kube-scheduler создаёт заявку сопоставления узла и подов на kube-apiserver
Конечно же не всегда нужно автоматическое распределение. При необходимости вы можете создать свой собственный планировщик в файле конфигурации пода, что приведёт к размещению на конкретном узле.
Kube Controller Manager
Kube Controller Manager необходим для мониторинга состояния вашего кластера, является основным компонентом в control plane. Он запускает процессы контроллеров, которые необходимы для выполнения рутинных операций, гарантируя, что текущее состояние кластера соответствует желаемому состоянию, указанному пользователем. Kube Controller Manager также управляется kube-scheduler.
Для того чтобы понять получше необходимость в Kube Controller Manager представим пример, где вы решили развернуть кластер с двумя репликами, одним общим хранилищем и т.д. Встроенный контроллер в Kube Controller Manager (Deployment Controller) гарантирует что будет создано две реплики, и если вдруг вы решите увеличить количество реплик, то он также сделает это ради вас.
Вот список некоторых особо важных контроллеров:
- Node Controller: отвечает за процесс мониторинга активности узла. Если вдруг узел не отвечает, то Node Controller оповещает об этом. Если же узел недоступен какое-то время, то запускается процесс пересоздания подов на другом узле.
- Replication Controller: собственно, отвечает за соблюдение настроек репликации
- Service Account & Token Controllers: Отвечает за учетные записи по умолчанию и токены доступа к API
- Deployment Controller: Отвечает за управление жизненным циклом развертываний, обеспечивая соответствие параметрам, заданным пользователем.
Для соблюдения отказоустойчивости в вашем кластере должно быть несколько узлов с компонентом Kube Controller Manager.
Мы также не лишены возможности создавать свои собственные контроллеры, но об этом не в этой статье.
Cloud Controller Manager (CCM)
Вы уже наверняка знаете, что почти все популярные облачные сервисы предоставляют возможность использования Kubernetes, и конечно необходимо управлять кластером в облаке. Возможность управления облачным кластером даёт компонент Cloud Controller Manager (CCM), который выступает как мост между нашим кластеров и API сервисом облачного провайдера.
Cloud Controller Manager (CCM) является компонентом узла управления (control plane node component). Но вы также можете запустить Cloud Controller Manager как надстройку Kubernetes, а не как часть узла управления.
Cloud Controller Manager включает группу контроллеров как и в случае с Kube Controller Manager. Для примера рассмотрим золотую троицу:
- Node Controller: используя
APIпровайдера облачного сервиса получает информацию о узлах, такую как имя узла, свободные ресурсы, статус узла и т.д. - Route controller: отвечает за настройку маршрутов в сети благодаря чему разные контейнеры на разных узлах могут обращаться друг к другу по сети. В зависимости от облачного провайдера также может выделять блоки IP-адресов
- Service controller: используется для развёртывания узлов балансировки нагрузки, назначения ip адресов, фильтрации сетевых пакетов

Комментарии